
Trabalho 0 – aquecimento (para 13/8)
O objetivo do trabalho é fazer uma análise experimental
do desempenho do algoritmo de Euclides para
encontrar o máximo divisor comum de dois números naturais.
-
Pesquise sobre o algoritmo de Euclides.
-
Implemente o algoritmo de Euclides.
-
Meça o número de passos feitos pelo algoritmo de Euclides
para calcular o o máximo divisor comum de dois números naturais
a e b,
para 1 ≤ a,b ≤ N.
Como o número máximo varia em função de N?
Como o número médio varia em função de N?
-
Pesquise sobre o desempenho do algoritmo de Euclides.
-
Compare as previsões teóricas com os seus resultados experimentais.
Trabalho 1 – ordenação (para 22/9)
O objetivo do trabalho é fazer uma análise experimental para
comparar alguns algoritmos de ordenação.
-
Implemente os algoritmos estudados em aula
(seleção, inserção, mergesort, quicksort, heapsort).
Escreva o programa mais simples possível para testar cada algoritmo.
Compare o esforço necessário para a implementação correta de cada algortimo.
-
Compare o desempenho dos algoritmos em
sequências de números inteiros geradas aleatoriamente.
Use sequências de 100 até 100000 números.
(E mais se for possível.)
Meça e compare os tempos de cada algoritmo.
-
Repita os testes com sequências especiais:
ordenadas em ordem crescente,
ordenadas em ordem descrescente,
com muitas repetições,
com poucas repetições.
-
No caso de mergesort e quicksort,
interrompa a recursão quando o subproblema for pequeno
e execute ordenação por inserção em cada subproblema.
No caso de quicksort,
faça o mesmo executando ordenação por inserção uma única vez,
ao final do processo.
Vale a pena fazer essas modificações?
A partir de quando?
Para qual definição de pequeno?
-
Adapte os seus programas para ordenar palavras.
Teste o desempenho de cada algoritmo
no arquivo BR4.txt contendo 10000 palavras
e
no arquivo BR5.txt contendo 100000 palavras.
Houve mudança do desempenho relativo dos algoritmos agora que
comparar valores é mais complicado?
Trabalho 2 – grafos (para 15/10)
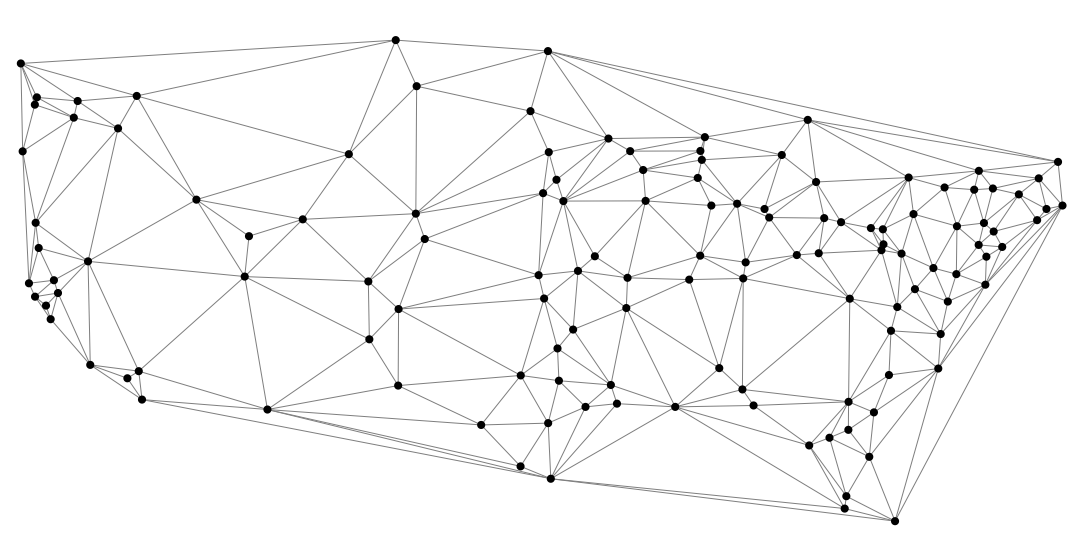 O grafo ao lado mostra 128 cidades da América do Norte.
Ele foi extraído do arquivo miles.dat do livro The Stanford GraphBase.
O arquivo map.txt representa esse grafo:
os vértices estão numerados de 1 a 128 e
cada linha lista uma aresta do grafo e o seu comprimento,
isto é,
duas cidades e a distância entre elas.
O grafo ao lado mostra 128 cidades da América do Norte.
Ele foi extraído do arquivo miles.dat do livro The Stanford GraphBase.
O arquivo map.txt representa esse grafo:
os vértices estão numerados de 1 a 128 e
cada linha lista uma aresta do grafo e o seu comprimento,
isto é,
duas cidades e a distância entre elas.
- Encontre uma árvore geradora mínima para esse grafo.
- Encontre o menor caminho entre a cidade 93 e a cidade 112.
- Encontre a árvore de menores caminhos a partir da cidade 104.
 Para cada um desses subgrafos, calcule o seu comprimento total.
Para cada um desses subgrafos, calcule o seu comprimento total.
Se quiser gerar uma figura, edite o arquivo map.eps para incluir
o subgrafo após a linha marcada subgraph no formato indicado.
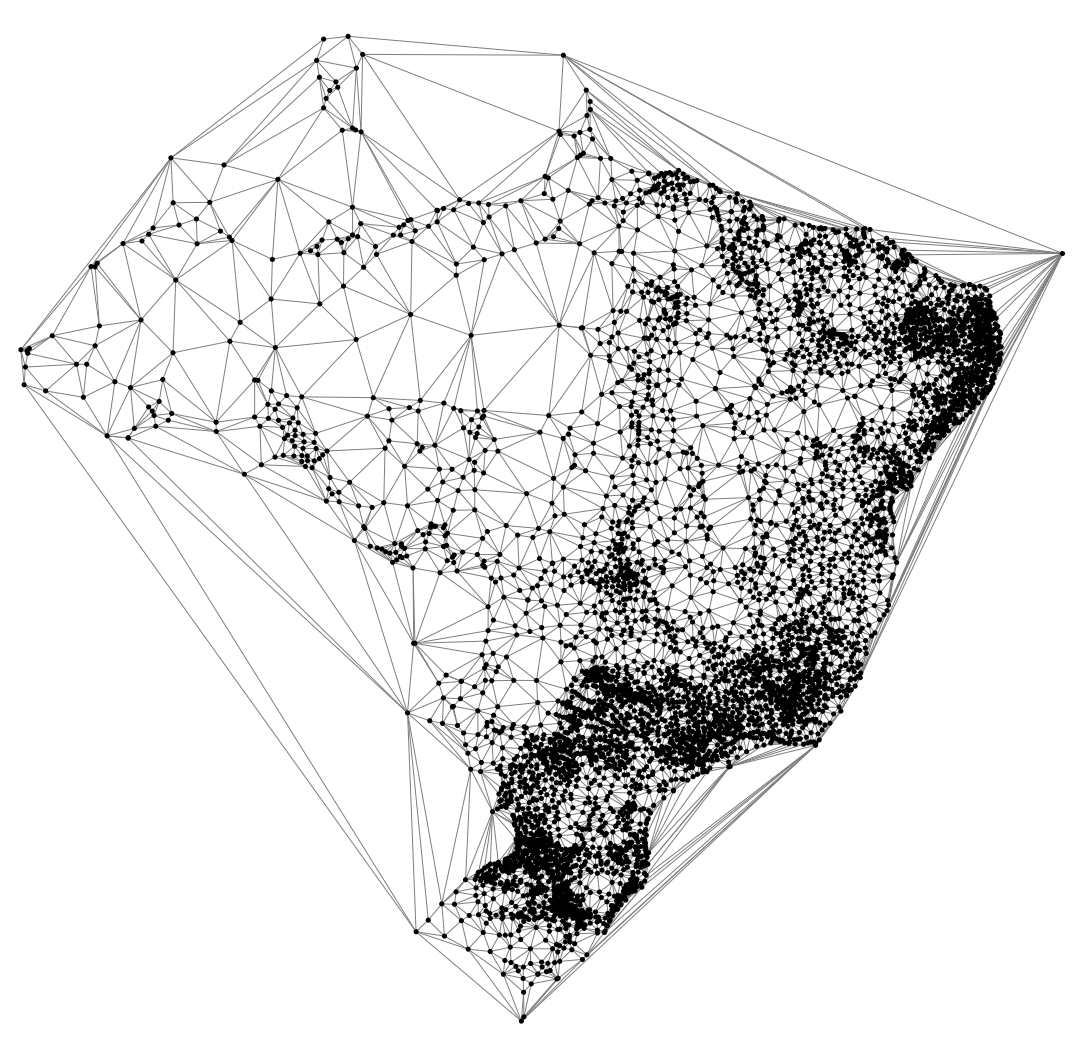
Faça o mesmo para o grafo das 5565 sedes dos municípios do Brasil,
encontrando o menor caminho entre a cidade 1 e cidade 2646,
e a árvore de menores caminhos a partir da cidade 2646.
Veja uma
imagem do grafo e o programa ps.
Trabalho 3 – fecho convexo (para 3/11)
O objetivo do trabalho é comparar algoritmos que calculam o fecho
convexo de um conjunto de pontos no plano.
-
Implemente o algoritmo de Jarvis e o algoritmo de Graham,
nas suas duas variantes.
 (Implemente também outros algoritmos se quiser.)
Escreva o programa mais simples possível para cada algoritmo.
Não se preocupe com interfaces gráficas.
(Implemente também outros algoritmos se quiser.)
Escreva o programa mais simples possível para cada algoritmo.
Não se preocupe com interfaces gráficas.
-
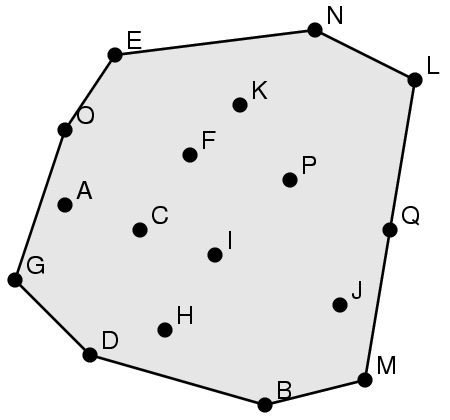
Teste os seus programas no seguinte conjunto de pontos:
A B C D E F G H I J K L M N O P Q
x 3 11 6 4 5 8 1 7 9 14 10 17 15 13 3 12 16
y 9 1 8 3 15 11 6 4 7 5 13 14 2 16 12 10 8
A solução é B M L N E O G D.
Note que Q não faz parte da solução.
A
figura ao lado
mostra a solução e foi gerada por um
programa
em
PostScript.
Teste também para as 128
cidades da América do Norte
e para as 5565
sedes dos municípios do Brasil,
e compare a sua solução com as figuras acima.
Quantos vértices tem o fecho convexo em cada caso?
-
Compare o desempenho dos algoritmos implementados em conjuntos de pontos
gerados aleatoriamente
dentro de um retângulo,
dentro de um triângulo,
dentro de um círculo,
e sobre o círculo.
Use conjuntos de 100 até 100000 pontos.
(E mais se for possível.)
Compare os tempos de cada algoritmo e
também o esforço necessário para sua implementação.
-
Refaça os testes do item anterior incorporando eliminação de pontos interiores.
Vale a pena eliminar pontos interiores?
Qual as frações do tempo total que levam
a eliminação de pontos interiores e
o cálculo do fecho convexo após essa eliminação?
-
Avalie o papel do passo de ordenação no desempenho global dos seus programas.
Qual a diferença entre usar
um algoritmo quadrático ou um algoritmo O(n log n)?
Trabalho 4 – interseção de segmentos de retas (para 8/12)
Neste trabalho estudaremos o problema de detectar se em uma coleção de segmentos no plano, algum par se intersecta. Para isso utilizaremos o algoritmo de "varredura por retas verticais".
Esse algoritmo faz uso de uma estrutura de dados X, capaz de implementar as operações de: Inserção, Remoção, Sucessor/Antecessor.
Nos itens que seguem, o aluno deve escolher apenas um item especial (marcado com *) para implementar.
-
Implemente o algoritmo de varredura (utilizando uma estrutura X arbitrária) para detectar:
- Se dois segmentos de uma coleção se intersectam.
- *Se uma sequência de segmentos constitui um polígono.
- Implemente as estruturas:
- lista duplamente encadeada
- árvore binária de busca
- * red-black trees
-
Compare o desempenho do algoritmo (utilizando todas as estruturas implementadas no item anterior) para detectar interseções dos segmentos gerados pelos seguintes códigos python (para N = 10, 100, 1000... até onde der):
import random
N = 10
print "x1 y1 x2 y2"
for i in range(N/2):
x = random.random()*N
y = random.random()*N
print x, y, x + 1.2, y - .2
print x, y + .5, x + .5, y + 2.5
import random
N = 10
print "x1 y1 x2 y2"
for i in range(N):
a = random.random() * N
print i, a, i + N, a
N = 10
print "x1 y1 x2 y2"
for i in range(N):
print i, i, i + N, i
- Caso tenha implementado o item 1b, rode também o algoritmo em um polígono regular com N lados.
-
Avalie o desempenho de cada uma das estruturas de dados implementadas.
Last update:
Thu Nov 26 13:28:29 BRST 2015
. Logo borrowed from
wikipedia.